Technologies Used
Project Overview
How much can you compress data before a machine learning model can no longer make accurate predictions? I worked with a team of 3 graduate students to explore this question using mathematical optimization techniques from a graduate-level Linear Programming course (EC ENGR 236A) at UCLA.
The goal was to classify clothing images (T-shirts, dresses, and coats) from the Fashion-MNIST dataset while using as few bits of information as possible. Since there are 3 clothing types, the information-theoretical minimum needed to distinguish between them is 2 bits of information. Our centralized model achieved 87% accuracy using 160 bits and still maintained 67% accuracy with just 4 bits!
Key Results
The Problem
We worked with 1000 28×28 black-and-white pixel images of a piece of clothing — that's 784 numbers representing brightness values. Normally, a machine learning model would look at all 784 8-bit values to decide if it's a T-shirt, a dress, or a coat. That's 6272 bits of data per image!

But the model doesn't actually need all of this data! We can do with much less per image. This is the feature compression problem, and it matters for real-world applications like:
- Sending data over limited bandwidth networks
- Scaling models to run on huge datasets
- Running machine learning on devices with limited memory
- Privacy-preserving machine learning (sending less data = less exposure)
- Distributed systems where multiple sensors need to share compressed information
For example, suppose a model is responsible for identifying harmful content on social media. For example, Instagram handles around 100 million posts per day. At this scale, reductions in data size per image means huge cost savings.
There are a few standard approaches to feature-compression. For example, Uniform Scalar Quantization reduces the number of bits per pixel. At best, if each pixel is reduced to one bit, we can get down to 784 bits per image.
Unfortunately, the data is already quite compressed, so we can't do much better with simple methods. But we can do much better! Many of the pixels are totally unimportant for classification! Also, we're throwing away information indiscreetly! There might be some critical pixels where we need more than one bit to represent them accurately.
So instead of assigning the same number of bits to each pixel, what if we create another model to optimize the bit allocation? This model would use training data to decide which pixels are most important for classification, and allocate bits accordingly. That's exactly what we did using Integer Linear Programming.
Two Approaches
Centralized
One encoder looks at the entire image and compresses it into a fixed number of bits. This approach achieved the best results because it can see relationships across the whole image.
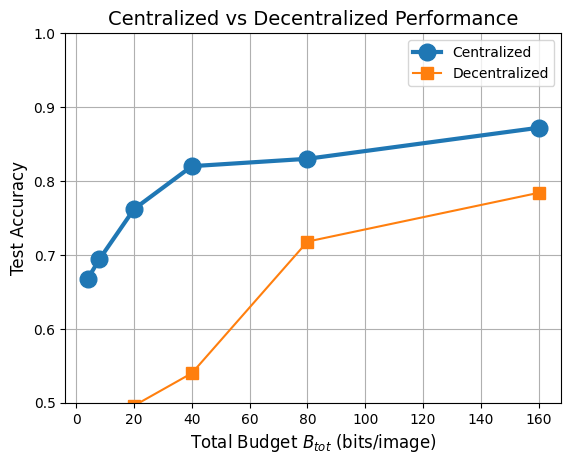
Best accuracy: 87% accuracy @ 160 bits
Best compression: 67% accuracy @ 4 bits
Decentralized
Four encoders each look at one quadrant of the image independently, then send their compressed data to a central classifier. This is harder because each encoder can't see what the others are doing, but it's more realistic for distributed sensor networks.
79% accuracy @ 160 bits
Extreme compression unviable
Results
The graph below shows how accuracy improves as we allow more bits for compression. Even with very few bits, the centralized model maintains reasonable accuracy, and approaches the uncompressed baseline (89.8%) with just 160 bits per image. That's a 97.5% reduction in data size!
Technical Approach
The project used linear programming and integer linear programming, which are mathematical optimization techniques, to find the best way to compress the data. Instead of using neural networks (which learn patterns through trial and error), we formulated the compression problem as a mathematical equation and solved it directly using CVXPY. Unlike neural networks, this approach guarantees the optimal solution given the constraints.
1. Linear Classifier Training
Train a classifier on the full 784 features using LP with regularization. This makes most feature weights zero or near-zero, identifying which pixels actually matter for classification.
2. Bit Allocation (ILP)
Use integer linear programming to decide how many bits to assign each feature. Important features get more bits; unimportant features get zero bits and are discarded entirely.
3. Quantization & Retraining
Compress feature values to their allocated bit depths, then retrain the classifier on the quantized data. The model learns to work with the compressed representation.
What I Learned
- • How to apply graduate-level optimization theory to practical machine learning problems
- • Trade-offs between compression ratio and prediction accuracy
- • Centralized vs. decentralized system architectures and their real-world implications
- • Using CVXPY for convex and integer optimization problems in Python
- • Collaborating with graduate students on a research-level engineering problem
Course Context
This was the final project for EC ENGR 236A: Linear Programming, a graduate-level course at UCLA completed in December 2025. The course covered both mathematical theory and engineering applications of linear programming, rigorously bridging the gap between my two majors (Computer Engineering and Applied Mathematics).
I worked on this project with a team of 3 graduate students. Taking graduate coursework as an undergraduate and collaborating with grad students helped me develop skills in mathematical modeling, optimization algorithms, and translating theory into working code.